

Google DeepMind telah membuat kemajuan signifikan dalam penelitian kecerdasan buatan (AI) mereka dengan menghadirkan model autoregresif baru yang disebut “Mirasol3B” pada hari Selasa. Model baru ini bertujuan untuk meningkatkan pemahaman input video panjang dan menunjukkan pendekatan inovatif terhadap pembelajaran multimodal, memproses data audio, video, dan teks dengan cara yang lebih terintegrasi dan efisien.
Menurut Isaac Noble, seorang insinyur perangkat lunak di Google Research, dan Anelia Angelova, seorang ilmuwan riset di Google DeepMind, yang ikut menulis postingan blog panjang lebar tentang penelitian mereka, tantangan membangun model multimodal terletak pada heterogenitas modalitas. Mereka menjelaskan bahwa beberapa modalitas mungkin tersinkronisasi dengan baik dalam waktu (misalnya audio, video) namun tidak selaras dengan teks. Selain itu, volume data yang besar dalam sinyal video dan audio jauh lebih besar dibandingkan dengan teks, sehingga ketika digabungkan dalam model multimodal, video dan audio sering kali tidak dapat dikonsumsi sepenuhnya dan perlu dikompresi secara tidak proporsional. Masalah ini diperburuk pada input video yang lebih panjang.
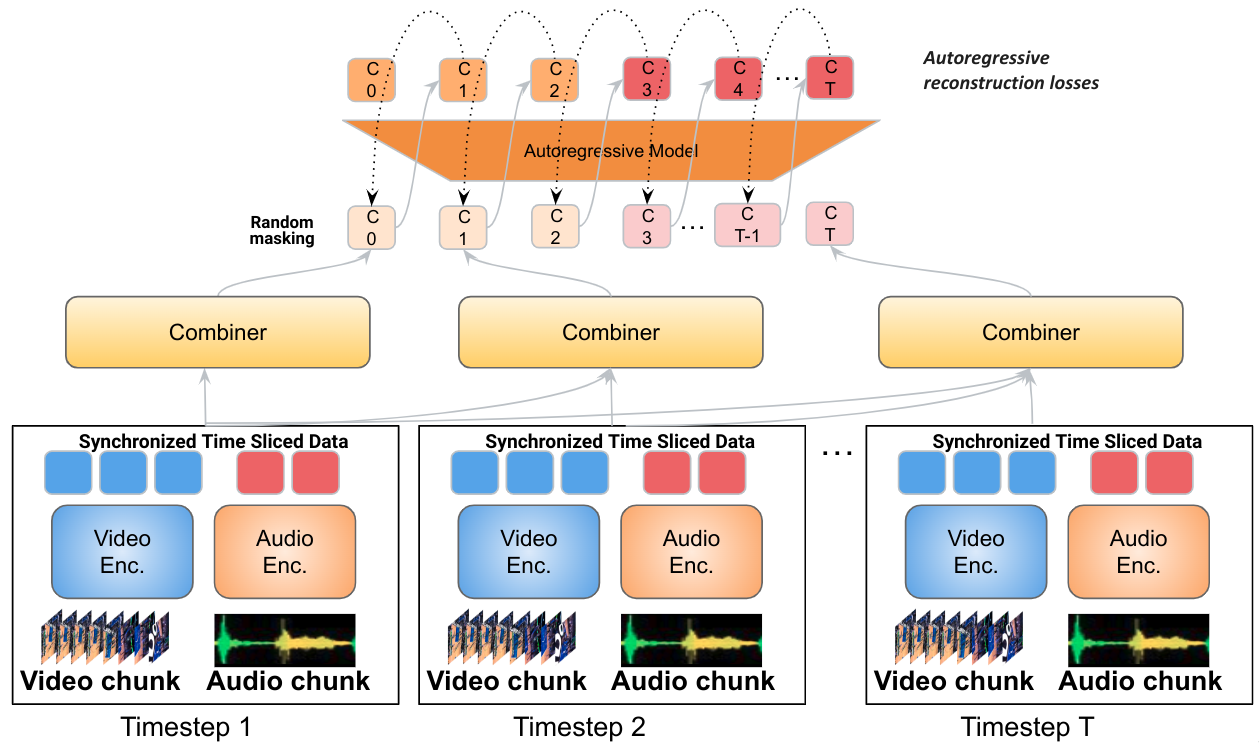
Model baru, Mirasol3B, adalah model multimodal autoregresif yang membagi pembelajaran menjadi pemodelan autoregresif untuk modalitas media yang selaras dengan waktu dan modalitas yang tidak selaras dengan waktu. Model ini terdiri dari komponen autoregresif yang memadukan dan bersama-sama mempelajari sinyal-sinyal yang selaras dengan waktu, yang terjadi pada tingkat yang berbeda, dan komponen non-autoregresif yang memodelkan modalitas yang tidak selaras dengan waktu.
Google Research telah mendorong model multi-modal yang dapat secara fleksibel menangani banyak modalitas berbeda secara bersamaan, baik sebagai masukan model maupun sebagai keluaran model. Kualitas dan kemampuan model generatif untuk citra, video, dan audio telah menunjukkan kemajuan yang sungguh menakjubkan dan luar biasa pada tahun 2022. Model baru, Mirasol3B, merupakan kemajuan signifikan dalam pembelajaran multimodal dan pemrosesan data audio, video, dan teks secara lebih terintegrasi. dan cara yang efisien.
Pendekatan baru untuk pembelajaran multimodal
Untuk mengatasi kerumitan tugas tersebut, model Mirasol3B Google secara strategis membagi pemodelan multimoda dengan menggunakan model autoregresif yang berbeda. Model-model ini memproses masukan berdasarkan karakteristik spesifik dari modalitas yang terlibat.
“Pendekatan kami melibatkan penggabungan elemen autoregresif untuk modalitas yang disinkronkan dalam waktu, seperti audio dan video, di samping komponen autoregresif yang berbeda untuk modalitas yang mungkin tidak selaras secara sementara namun tetap mengikuti pola berurutan, seperti masukan teks seperti judul atau deskripsi, ” jelas Noble dan Angelova.
Pengumuman ini muncul pada saat industri teknologi berupaya memanfaatkan kekuatan AI untuk menganalisis dan memahami sejumlah besar data dalam berbagai format. Mirasol3B dari Google mewakili langkah maju yang signifikan dalam upaya ini, membuka kemungkinan baru untuk aplikasi seperti menjawab pertanyaan video dan jaminan kualitas video berdurasi panjang.
Google DeepMind telah mengembangkan model autoregresif baru yang disebut “Mirasol3B” yang bertujuan untuk meningkatkan pemahaman tentang masukan video berdurasi panjang. Model yang ada saat ini mendekati pemodelan video dengan mengekstraksi semua informasi sekaligus, tanpa informasi temporal yang memadai. Untuk mengatasi hal ini, model baru ini menerapkan strategi pemodelan autoregresif yang mengkondisikan representasi video dan audio yang dipelajari bersama untuk satu interval waktu pada representasi fitur dari interval waktu sebelumnya. Ini menjaga informasi sementara.
Video pertama-tama dipartisi menjadi potongan-potongan video yang lebih kecil, dan setiap potongan dapat terdiri dari 4-64 frame. Fitur-fitur yang sesuai dengan setiap potongan kemudian diproses oleh modul pembelajaran yang disebut Penggabung, yang menghasilkan representasi fitur audio dan video gabungan pada langkah saat ini. Langkah ini mengekstrak dan memadatkan informasi terpenting per bagian. Selanjutnya, representasi fitur gabungan diproses dengan Transformator autoregresif, yang memberikan perhatian pada representasi fitur sebelumnya dan menghasilkan representasi fitur gabungan untuk langkah berikutnya. Akibatnya, model tersebut mempelajari cara untuk merepresentasikan tidak hanya masing-masing bagian tetapi juga bagaimana bagian tersebut berhubungan secara temporal.
Pengembangan Mirasol3B menandai kemajuan signifikan dalam bidang pembelajaran mesin multimodal. Dengan kemampuannya menangani beragam jenis data dan menjaga koherensi temporal dalam pemrosesan, model ini menghasilkan kinerja canggih di beberapa tolok ukur sekaligus lebih efisien dalam parameter dibandingkan pendahulunya.
Model autoregresif adalah model generatif kuat yang sangat cocok untuk data yang muncul secara berurutan, memodelkan probabilitas nilai saat ini, yang dikondisikan pada nilai sebelumnya. Informasi video dan audio bersifat berurutan tetapi juga tersinkronisasi secara kasar dengan waktu. Pada saat yang sama, modalitas lain, seperti teks, mungkin disediakan secara global per video sebagai konteks dan diterapkan pada keseluruhan video, bukan pada bagian tertentu. Pemodelan autoregresif video dan audio yang selaras dengan waktu dijelaskan dalam model Mirasol3B. Model ini menerapkan strategi pemodelan autoregresif yang mengkondisikan representasi video/audio yang sesuai dengan interval waktu pada representasi fitur dari interval waktu sebelumnya. Representasi ini dipelajari bersama oleh Penggabung. Video pertama-tama dipartisi menjadi beberapa bagian, dan model memproses setiap bagian secara otomatis dalam waktu.
Potensi pemanfaatan pada platform YouTube
Google berpotensi menjajaki penggunaan model Mirasol3B di YouTube, platform video online terbesar di dunia dan salah satu sumber pendapatan utama perusahaan. Model ini dapat digunakan untuk meningkatkan pengalaman dan keterlibatan pengguna dengan menyediakan lebih banyak fitur dan fungsi multimodal. Hal ini termasuk membuat keterangan dan ringkasan untuk video, menjawab pertanyaan dan memberikan umpan balik, membuat rekomendasi dan iklan yang dipersonalisasi, dan memungkinkan pengguna membuat dan mengedit video mereka sendiri menggunakan input dan output multimodal.
Misalnya, model ini dapat menghasilkan teks dan ringkasan untuk video berdasarkan konten visual dan audio, dan memungkinkan pengguna mencari dan memfilter video berdasarkan kata kunci, topik, atau sentimen. Hal ini dapat meningkatkan aksesibilitas dan kemampuan menemukan video, sehingga membantu pengguna menemukan konten yang mereka cari dengan lebih mudah dan cepat. Selain itu, model ini dapat digunakan untuk menjawab pertanyaan dan memberikan masukan bagi pengguna berdasarkan konten video, seperti menjelaskan arti suatu istilah, memberikan informasi atau sumber daya tambahan, atau menyarankan video atau playlist terkait.
Penerapan potensial model Mirasol3B di YouTube menunjukkan keserbagunaan dan dampak pembelajaran mesin multimodal dalam meningkatkan pengalaman pengguna dan interaksi dengan konten video. Dengan memanfaatkan kemampuan model ini, YouTube dapat semakin memperkaya platformnya dengan fitur-fitur canggih yang memenuhi beragam kebutuhan dan preferensi penggunanya, sehingga pada akhirnya berkontribusi pada pengalaman menonton yang lebih menarik dan dipersonalisasi.
Respons yang bervariasi dari komunitas kecerdasan buatan
Pengumuman model Mirasol3B telah memicu minat dan kegembiraan yang signifikan dalam komunitas kecerdasan buatan, sekaligus menimbulkan skeptisisme dan kritik. Beberapa ahli memuji model ini karena keserbagunaan dan skalabilitasnya, serta menyatakan optimisme mengenai potensi penerapannya di berbagai domain.
Misalnya, Leo Tronchon, seorang insinyur riset ML di Hugging Face, menyatakan minatnya pada model seperti Mirasol yang menggabungkan lebih banyak modalitas, khususnya audio dan video. Dia menyoroti kelangkaan model kuat di ruang terbuka yang memanfaatkan audio dan video, serta menekankan potensi kegunaan model tersebut pada platform seperti Hugging Face.
Di sisi lain, Gautam Sharda, seorang mahasiswa ilmu komputer di University of Iowa, menyuarakan keprihatinan tentang tidak adanya kode, bobot model, data pelatihan, atau API untuk model Mirasol3B. Dia menyatakan keinginannya untuk melihat pelepasan aset berwujud lebih dari sekedar makalah penelitian.
Beragamnya reaksi terhadap pengumuman model Mirasol3B mencerminkan lanskap kompleks penelitian dan pengembangan AI, yang mencakup antusiasme terhadap kemajuan teknologi dan evaluasi kritis terhadap implementasi praktis dan aksesibilitas.
Titik kritis yang berarti bagi masa depan kecerdasan buatan
Pengenalan model Mirasol3B mewakili tonggak penting dalam bidang kecerdasan buatan dan pembelajaran mesin, yang menunjukkan ambisi dan kepemimpinan Google dalam mengembangkan teknologi mutakhir yang berpotensi meningkatkan dan mengubah kehidupan manusia. Namun kemajuan ini juga menghadirkan tantangan dan peluang bagi para peneliti, pengembang, regulator, dan pengguna AI. Penting untuk memastikan bahwa model dan penerapannya selaras dengan nilai-nilai dan standar etika, sosial, dan lingkungan hidup masyarakat.
Ketika dunia menjadi lebih multimoda dan saling terhubung, menumbuhkan budaya kolaborasi, inovasi, dan tanggung jawab di antara para pemangku kepentingan dan masyarakat sangatlah penting. Hal ini akan berkontribusi dalam menciptakan ekosistem AI yang lebih inklusif dan beragam yang dapat memberikan manfaat bagi semua orang.
Pengumuman tersebut telah menimbulkan beragam minat dan skeptisisme dalam komunitas kecerdasan buatan. Meskipun beberapa pakar memuji model ini karena keserbagunaan dan skalabilitasnya, ada pula yang menyuarakan keprihatinan tentang tidak adanya aset berwujud di luar makalah penelitian, seperti kode, bobot model, data pelatihan, atau API. Keragaman reaksi ini mencerminkan lanskap kompleks penelitian dan pengembangan AI, yang mencakup antusiasme terhadap kemajuan teknologi dan evaluasi kritis terhadap implementasi praktis dan aksesibilitas.
Kesimpulannya, pengenalan model Mirasol3B menggarisbawahi potensi pembelajaran mesin multimodal untuk merevolusi berbagai bidang, sekaligus menyoroti pentingnya pertimbangan etis dan penerapan yang bertanggung jawab. Hal ini mewakili langkah maju yang signifikan dalam memajukan kemampuan AI dan menggarisbawahi perlunya upaya kolaboratif untuk memastikan bahwa kemajuan ini selaras dengan nilai-nilai dan standar masyarakat.
Sumber:
https://venturebeat.com/ai/google-deepmind-breaks-new-ground-with-mirasol3b-for-advanced-video-analysis/
https://blog.research.google/2023/11/scaling-multimodal-understanding-to.html?m=1
http://blog.research.google/2023/01/google-research-2022-beyond-language.html?m=1
https://arxiv.org/pdf/2311.05698.pdf
https://www.linkedin.com/posts/googleresearch_introducing-mirasol-a-multimodal-model-for-activity-7130323647172362241-JP6h?trk=public_profile_like_view
https://openaccess.thecvf.com/content/CVPR2023/papers/Yoo_Towards_End-to-End_Generative_Modeling_of_Long_Videos_With_Memory-Efficient_Bidirectional_CVPR_2023_paper.pdf
https://openreview.net/forum?id=rJgsskrFwH
https://the-decoder.com/googles-mirasol-pushes-the-boundaries-of-ai-video-understanding/
https://miro.medium.com/v2/resize:fit:875/0*7zXqcdgXIgyqnwxy.p